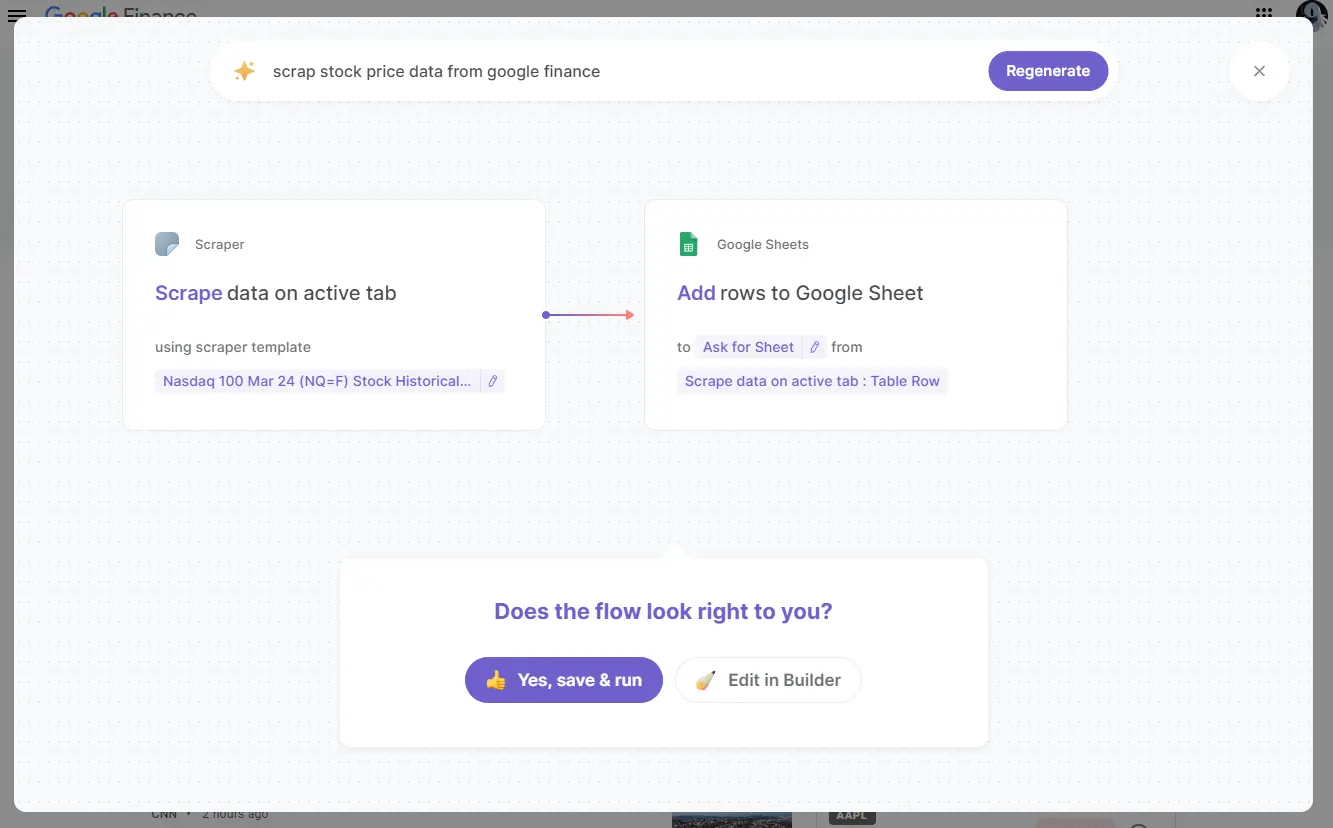
Use Python to scrape stock price data from websites.
By the way, we're Bardeen, we build a free AI Agent for doing repetitive tasks.
If you're into scraping, check out our AI Web Scraper. It automates data extraction and handles IP rotation, CAPTCHAs, and more.
Web scraping is a powerful technique that allows you to extract data from websites, and it's particularly useful for gathering stock market data. In this step-by-step guide, we'll walk you through the process of scraping stock prices and other financial information using Python. We'll cover the best libraries and tools for the job, show you how to set up your environment, and provide code snippets to help you extract data efficiently.
When scraping stock data, it's crucial to select the optimal libraries to ensure efficient and reliable data extraction. Here are some key considerations:
For large-scale scraping projects, using a service like ScraperAPI can significantly enhance your scraping capabilities. ScraperAPI offers features such as:
By leveraging these libraries and tools, you can build a robust and efficient stock data scraping pipeline that can handle various challenges and deliver accurate results.
Before diving into web scraping with Python, it's essential to set up your environment properly. Here's a step-by-step guide:
To enhance your scraping capabilities and handle challenges like IP blocking or CAPTCHAs, consider using ScraperAPI. Here's how to configure it with Python:
By setting up your environment correctly and leveraging tools like ScraperAPI, you'll be well-prepared to tackle web scraping tasks efficiently and effectively.
Save more time with web scraping by using Bardeen's scraper integration. With Bardeen, automate your scraping tasks without any coding.
To extract real-time stock data using Python, you can connect to financial websites like Investing.com and scrape the relevant information. Here's how to do it using the BeautifulSoup library:

Here's a complete example that extracts stock data for Apple Inc.:
import requests
from bs4 import BeautifulSoup
url = 'https://www.investing.com/equities/apple-computer-inc'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
stock_name = soup.find('h1', {'class': 'text-2xl'}).text.strip()
stock_price = soup.find('span', {'class': 'text-2xl'}).text.strip()
stock_change = soup.find('div', {'class': 'instrument-price_change-percent__19cas'}).text.strip()
print(f"Stock Name: {stock_name}")
print(f"Current Price: {stock_price}")
print(f"Change: {stock_change}")
This script will output the stock name, current price, and change percentage for Apple Inc.
Keep in mind that websites may change their HTML structure over time, so you might need to adjust the class names or selectors accordingly. Additionally, be respectful of the website's terms of service and avoid excessive scraping that could overload their servers. Consider using a web scraping tool to simplify the process and handle challenges like IP rotation and CAPTCHA solving.
When scraping stock market data, you may encounter various challenges, such as dynamic content loaded by JavaScript. To overcome this, you can use tools like Selenium, which allows you to interact with web pages and wait for dynamic content to load before extracting the desired data.
Here's an example of using Selenium with Python to handle dynamic content:

from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://example.com')
# Wait for the dynamic content to load
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'dynamic-content'))
)
# Extract the desired data
data = element.text
driver.quit()
In addition to technical challenges, it's crucial to consider the legal and ethical aspects of scraping stock market data. While the data itself may be publicly available, some websites have terms of service that prohibit automated data collection. It's important to review and comply with these terms to avoid potential legal issues.
Here are some best practices for ethical web scraping:
Remember, while web scraping can be a powerful tool for collecting stock market data, it's essential to use it ethically and legally to maintain the integrity of your data and avoid potential consequences.
Bardeen can help you automate repetitive scraping tasks. Save time by using Bardeen's scraper integration.
Once you've successfully scraped stock market data using Python, it's important to store it in a format that allows for easy access and analysis. One common approach is to store the data in CSV (Comma-Separated Values) files.
To store scraped data in a CSV file using Python, you can follow these steps:
open() function.csv module to create a CSV writer object.Here's a code snippet demonstrating how to store scraped stock data in a CSV file:
import csv
# Scraped data
data = [
['AAPL', '150.42', '+1.23'],
['GOOGL', '2,285.88', '-5.67'],
['AMZN', '3,421.37', '+12.34']
]
# Write data to CSV file
with open('stock_data.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Stock', 'Price', 'Change']) # Write header
writer.writerows(data) # Write data rows
Once the scraped stock data is stored in a CSV file, you can leverage it for various purposes:
By storing scraped stock data in a structured format like CSV, you can easily import it into other tools or platforms, such as Excel, Python data analysis libraries (e.g., Pandas), or data visualization tools (e.g., Matplotlib or Plotly), for further analysis and decision-making.
Remember to handle the scraped data responsibly and ensure compliance with the terms of service and legal requirements of the websites from which you scrape the data.



SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













