
Scrape Redfin listings using Python libraries and browser automation tools.
By the way, we're Bardeen, we build a free AI Agent for doing repetitive tasks.
If you're into scraping, you'll love our AI Web Scraper. It helps extract data from websites like Redfin with ease. Save time and get accurate data.
Scraping Redfin property listings is a valuable skill for real estate professionals and data enthusiasts in 2024. By extracting key information from Redfin, you can gain insights into market trends, property details, and historical data to make informed decisions. In this comprehensive guide, we'll walk you through the step-by-step process of scraping Redfin efficiently, covering both manual and automated methods using cutting-edge tools like Bardeen.
Want to know the secrets to extracting valuable data from Redfin listings? Curious about the legal and ethical considerations involved? Keep reading to discover how to set up your own scraper, handle challenges, and maintain data integrity. By the end of this guide, you'll have the knowledge and tools to scrape Redfin like a pro and unlock a wealth of real estate data at your fingertips.
Redfin is a popular real estate platform that provides a wealth of data for property listings, market trends, and historical information. To effectively scrape Redfin data, it's crucial to understand its data structure and layout. By examining how the data is presented on the website, you can identify the best points for extraction and ensure a comprehensive data collection process.
Take a closer look at Redfin's website structure to determine the most efficient way to extract data. Pay attention to the organization of property listings, the placement of key details like price, square footage, and location, and any pagination or dynamic loading of content. This analysis will help you develop a targeted scraping strategy.
For example, let's say you notice that Redfin displays 20 property listings per page and uses AJAX to load more results as the user scrolls. This information will guide your approach to handling pagination and ensuring you capture all available listings.
Redfin offers a rich dataset that includes property listings, historical sales data, and market trends. Understanding the types of data available will help you focus your scraping efforts on the most valuable information for your needs.
By identifying the specific data points you want to extract, you can tailor your scraping script to capture the most relevant information efficiently.
In this section, we explored the importance of analyzing Redfin's data structure and layout to optimize your scraping approach. We also discussed the various types of data available on the platform, including property listings, historical data, and market trends.
Next up, we'll dive into the legal and ethical considerations surrounding data scraping to ensure you're operating within the bounds of Redfin's terms of service and respecting data privacy laws. For more on these considerations, read about ethical scraping methods.
When scraping data from Redfin, it's crucial to understand and adhere to legal and ethical guidelines to avoid potential complications. Redfin's robots.txt file outlines specific rules and restrictions for web crawlers and scrapers, ensuring that data extraction is performed responsibly and within the platform's terms of service.
Redfin's robots.txt file serves as a roadmap for web scrapers, specifying which pages or sections of the website are allowed to be accessed and scraped. By following these guidelines, you can avoid legal issues and maintain a positive relationship with Redfin.
For instance, if Redfin's robots.txt file prohibits scraping of certain pages, such as user profiles or sensitive financial data, respecting these restrictions is essential to prevent potential legal repercussions.
In addition to adhering to Redfin's specific guidelines, it's important to be aware of broader data privacy laws and regulations. When scraping personal information from property listings, such as seller names or contact details, handle this data with care and ensure compliance with relevant legislation like the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA).
Ethical scraping practices also involve being mindful of the impact on Redfin's servers and infrastructure. Avoid aggressive scraping techniques that could overload or disrupt the website's performance, and consider implementing throttling mechanisms to limit the frequency of your requests.
By prioritizing legal compliance and ethical conduct, you can build trust with Redfin and the wider real estate community while still leveraging the valuable data available for your analysis and decision-making.
Remember, responsible data scraping is not only a legal obligation but also a reflection of your commitment to integrity and professionalism in the real estate industry.
Save time and boost productivity by using Redfin playbooks. Get the data you need without the hassle.
Next, we'll explore the tools and technologies that can improve your Redfin scraping process while ensuring efficiency and reliability.
When scraping data from Redfin, it's essential to understand and adhere to legal and ethical guidelines to avoid potential complications. Redfin's robots.txt file outlines specific rules and restrictions for web crawlers and scrapers, ensuring that data extraction is performed responsibly and within the platform's terms of service. Additionally, being mindful of data privacy laws and handling personal data ethically is crucial to maintain trust and compliance.
Redfin's robots.txt file serves as a roadmap for web scrapers, specifying which pages or sections of the website are allowed to be accessed and scraped. By following these guidelines, you can avoid legal issues and maintain a positive relationship with Redfin.
For example, if Redfin's robots.txt file prohibits scraping of certain pages, such as user profiles or sensitive financial data, respecting these restrictions is essential to prevent potential legal repercussions. Failure to comply with these guidelines can result in your IP address being blocked or even legal action being taken against you.
When scraping data from Redfin, it's crucial to be mindful of data privacy laws and regulations. Property listings often contain personal information, such as seller names, contact details, and financial information. Handling this data ethically and securely is paramount to maintain trust and comply with relevant legislation like the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA).
Ensure that you only collect and store the data necessary for your specific purpose and have appropriate measures in place to protect the privacy and security of individuals' personal information. Avoid scraping or storing sensitive data that is not publicly available or essential for your analysis.
Responsible data handling practices not only protect individuals' privacy but also demonstrate your commitment to ethical and transparent data collection in the real estate industry. For more insights, check out ethical scraping methods.
Key takeaways: Adhering to Redfin's robots.txt guidelines and handling personal data ethically are essential for legal compliance and maintaining trust. Next, we'll explore the tools and technologies that can streamline your Redfin scraping process while ensuring efficiency and reliability.
To effectively scrape data from Redfin, it's crucial to leverage the right tools and technologies. Python libraries like BeautifulSoup and Scrapy provide powerful capabilities for parsing HTML and extracting relevant information. Additionally, browser automation tools such as Selenium can handle dynamic content that may be challenging to capture with basic scraping techniques. By combining these tools, you can create a robust and efficient scraping pipeline tailored to Redfin's data structure.
Additionally you may find the below video of Bardeen's No Code Scrape Guidance useful.
Python offers a rich ecosystem of libraries specifically designed for web scraping. BeautifulSoup, for instance, is a popular choice for parsing HTML and XML documents. With its intuitive API, BeautifulSoup allows you to navigate the parsed tree, search for specific elements, and extract the desired data.
On the other hand, Scrapy is a comprehensive web crawling and scraping framework. It provides a high-level API for defining spiders that can crawl websites, follow links, and extract structured data. Scrapy's built-in support for handling requests, cookies, and authentication makes it well-suited for scraping Redfin listings at scale.
While BeautifulSoup and Scrapy excel at scraping static content, some websites heavily rely on JavaScript to render data dynamically. Redfin, for example, may load property details asynchronously or require user interactions to access certain information. In such cases, browser automation tools like Selenium come to the rescue.
Selenium allows you to automate interactions with web browsers, simulating user actions like clicking buttons, filling forms, and scrolling. By combining Selenium with Python, you can create scripts that navigate through Redfin's pages, wait for dynamic content to load, and extract the desired data. This approach ensures that you can scrape even the most complex and interactive aspects of Redfin's website.
Key takeaways: Python libraries and browser automation tools form a powerful combination for efficient Redfin scraping. Next, we'll dive into a step-by-step guide to setting up your scraper and putting these tools into action.
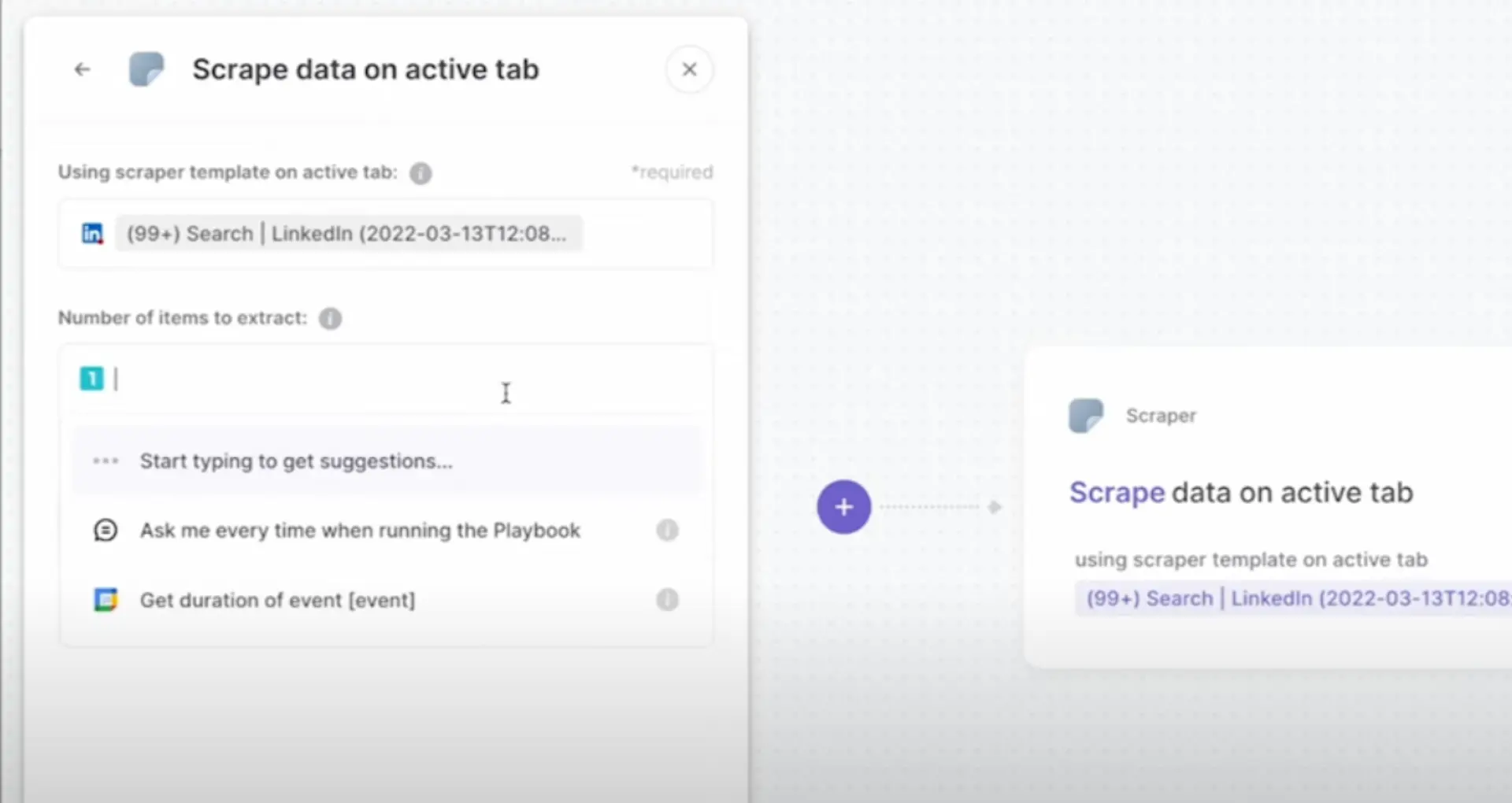
Save time scraping Redfin with Bardeen's Redfin playbooks. Automate the extraction of search results in one click.
Setting up a scraper for Redfin property data involves several key steps. First, you'll need to set up a Python environment and install the necessary libraries, such as requests, BeautifulSoup, and Scrapy. These tools will enable you to send HTTP requests, parse HTML content, and scrape data from websites efficiently. Next, you'll write a basic script that targets specific property pages or search results on Redfin, leveraging the libraries to navigate through the website's structure and retrieve the relevant information.
To begin your Redfin scraping journey, start by installing Python on your system if you haven't already. Once Python is set up, create a new virtual environment to keep your project dependencies isolated. This ensures a clean and organized workspace for your scraping endeavors.
With your virtual environment activated, proceed to install the essential libraries using pip. Open your terminal and run the following commands:
pip install requests - installs the requests library for sending HTTP requestspip install beautifulsoup4 - installs BeautifulSoup for parsing HTMLpip install scrapy - installs Scrapy for building robust scrapersThese libraries form the foundation of your scraping toolkit, enabling you to interact with Redfin's website and extract the desired property data effectively.
With your environment set up, it's time to dive into the coding aspect of your Redfin scraper. Begin by creating a new Python file and importing the necessary libraries:
import requests\nfrom bs4 import BeautifulSoup
Next, define the URL of the Redfin page you want to scrape. This could be a specific property listing or a search results page. Use the requests library to send a GET request to the URL:
url = "https://www.redfin.com/CA/Los-Angeles/1234-Main-St-90001/home/1234567"\nresponse = requests.get(url)
Once you have the response, create a BeautifulSoup object to parse the HTML content:
soup = BeautifulSoup(response.content, "html.parser")
From here, you can use BeautifulSoup's methods and selectors to locate and extract the desired property data. For example, to scrape the property address:
address = soup.find("span", class_="address").text
Repeat this process for other data points like price, bedrooms, bathrooms, and more. Store the extracted data in variables or a structured format like a dictionary for further processing or analysis.
Redfin search results often span multiple pages, and some content may be loaded dynamically using JavaScript. To ensure comprehensive data collection, you need to handle pagination and dynamically loaded content effectively.
For pagination, identify the URL pattern for subsequent pages and incorporate it into your scraper logic. You can use a loop to iterate through the pages, sending requests and extracting data from each page until you reach the end of the results.
To handle dynamically loaded content, you may need to employ additional tools like Selenium or Scrapy with a headless browser. These tools allow you to simulate user interactions and wait for the desired elements to load before extracting the data.
Key takeaways: Setting up a Redfin scraper involves configuring your Python environment, installing necessary libraries, and writing a script to extract property data. By leveraging pagination handling and dynamic content strategies, you can ensure a robust and comprehensive scraping process. In the next section, we'll explore how to handle challenges and maintain data integrity in your Redfin scraping endeavors.
Scraping data from Redfin comes with its own set of challenges, such as dealing with AJAX calls, navigating anti-scraping measures, and ensuring data accuracy. To overcome these hurdles and maintain the integrity of your scraped data, it's crucial to implement robust validation techniques, error handling mechanisms, and regular updates to your scraping script. By proactively addressing these challenges, you can ensure the reliability and usefulness of your scraped Redfin data for further analysis and decision-making.
Redfin, like many modern websites, heavily relies on AJAX (Asynchronous JavaScript and XML) to load data dynamically. This means that some property information may not be immediately available in the initial HTML response and requires additional requests to retrieve. To handle AJAX calls effectively, you can use tools like Selenium or Puppeteer, which allow you to interact with the website programmatically and wait for the desired data to load before extracting it.
Moreover, Redfin may employ various anti-scraping measures to protect its data and prevent unauthorized access. These measures can include IP blocking, rate limiting, or using CAPTCHAs. To bypass these obstacles, consider implementing techniques such as:
By adapting your scraping approach to circumvent anti-scraping measures, you can ensure a smoother and more reliable data extraction process from Redfin.
Ensuring the accuracy and integrity of your scraped Redfin data is paramount. Implementing robust data validation techniques helps identify and address any inconsistencies, errors, or missing values in your scraped dataset. Consider the following strategies:
By incorporating data validation and error handling into your scraping pipeline, you can maintain a high level of data quality and reliability, enabling more accurate analysis and decision-making based on the scraped Redfin data.
Save time scraping Redfin with Bardeen's Redfin playbooks. Automate the extraction of search results in one click.
Websites, including Redfin, undergo periodic updates and redesigns, which can impact the structure and selectors used in your scraping script. To ensure the longevity and effectiveness of your Redfin scraper, it's essential to regularly monitor and update your script to adapt to any changes in the website's layout or data presentation.
Keep an eye out for any modifications to the HTML structure, CSS classes, or data attributes used in your script. When changes occur, promptly update your script to reflect the new selectors and ensure seamless data extraction. Additionally, consider implementing automated monitoring systems that can alert you to any significant changes or scraping failures, allowing you to quickly identify and resolve issues.
By staying proactive and regularly updating your scraping script, you can maintain the reliability and effectiveness of your Redfin data extraction process over time.
Key takeaways: Scraping Redfin data presents challenges such as AJAX calls, anti-scraping measures, and website changes. Implementing data validation, error handling, and regular script updates ensures the accuracy and reliability of your scraped data for informed decision-making.
Mastering the art of scraping Redfin property listings empowers you to access valuable real estate data for informed decision-making and analysis.
This guide walked you through:
With these skills, you'll be well-equipped to unlock the treasure trove of Redfin data and make your mark in the real estate industry. Happy scraping, and may your data always be fresh and accurate!



SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













