




To scrape tables, use tools like BeautifulSoup or no-code options.
By the way, we're Bardeen, we build a free AI Agent for doing repetitive tasks.
If you're scraping tables, you might love our AI Web Scraper. It automates data extraction and syncs it with your apps, no coding needed.
Web scraping is a powerful technique that allows you to extract data from websites, and one of the most common targets for scraping is tables. Whether you're a beginner looking to learn the basics or an expert seeking to refine your skills, this guide will walk you through the process of web scraping tables step-by-step. We'll cover the tools and technologies involved, provide practical code examples, and discuss important considerations to help you scrape data effectively and ethically.
Introduction to Web Scraping Tables
Web scraping is the process of extracting data from websites, and it plays a crucial role in data-driven decision-making. By scraping tables from websites, you can gather valuable information for analysis and reporting, enabling you to make informed decisions based on real-world data.
The importance of web scraping lies in its ability to automate the data collection process, saving time and effort compared to manual methods. With web scraping tools, you can:
- Gather large volumes of data quickly and efficiently
- Access data from multiple sources and consolidate it into a single format
- Keep your data up-to-date by scheduling regular scraping tasks
- Gain insights into market trends, competitor pricing, and customer sentiment
When it comes to scraping tables specifically, the process involves identifying and extracting structured data from HTML tables on web pages. This data can range from financial reports and product catalogs to sports statistics and real estate listings.
By harnessing the power of web scraping automation, businesses and individuals can unlock valuable insights, make data-driven decisions, and gain a competitive edge in their respective fields.
Tools and Technologies for Web Scraping
When it comes to web scraping, there are various programming languages and tools available to suit different user expertise levels and project requirements. The most popular languages for web scraping include Python, R, and JavaScript, each offering its own set of libraries and frameworks for scraping.
Python, in particular, has gained significant popularity due to its simplicity and powerful libraries like BeautifulSoup and Scrapy. These libraries make it easy to parse HTML, navigate through web pages, and extract data efficiently into Excel.
For those who prefer a more visual approach or have limited coding experience, there are no-code tools available for web scraping. These tools provide user-friendly interfaces that allow you to point and click on the desired elements to extract data without writing any code. Some popular no-code web scraping tools include:
- ParseHub
- Octoparse
- Dexi.io
- Mozenda
On the other hand, if you have coding experience and require more flexibility and control over the scraping process, you can opt for coding solutions. These involve writing scripts using programming languages and leveraging libraries and frameworks specifically designed for web scraping.
Ultimately, the choice between no-code tools and coding solutions depends on your technical expertise, the complexity of the scraping task, and the level of customization required. Bardeen's scraper integration offers a powerful no-code solution for automating data extraction workflows.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Setting Up Your Environment for Scraping
Before you start web scraping with Python, you need to set up your development environment. Here are the steps to get you started:
- Install Python: Download and install the latest version of Python from the official website (python.org). Make sure to check the option to add Python to your PATH during the installation process.
- Choose an IDE or text editor: Select an Integrated Development Environment (IDE) or text editor to write your Python code. Popular choices include PyCharm, Visual Studio Code, and Sublime Text.
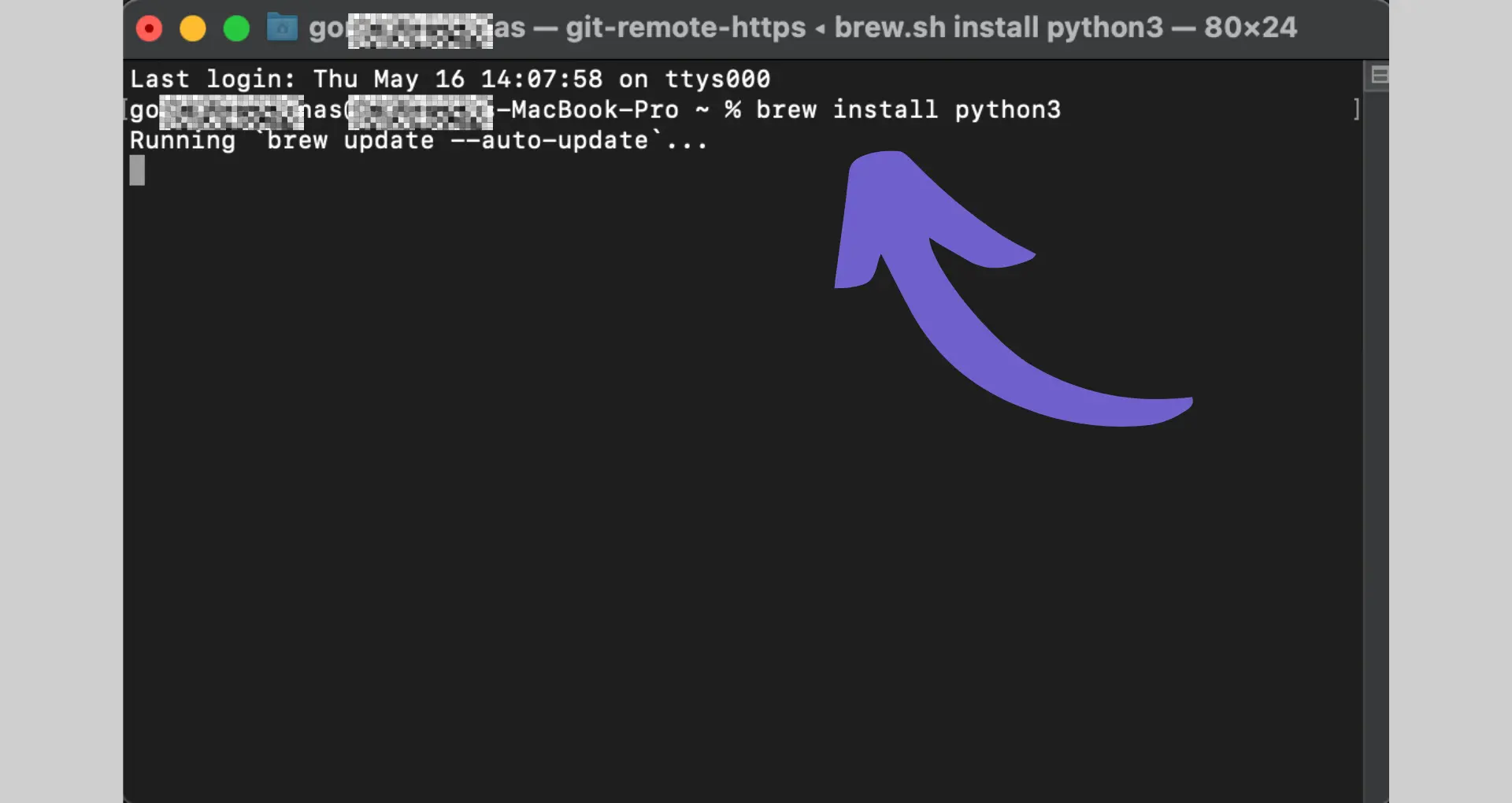
- Create a virtual environment (optional): It's a good practice to create a virtual environment for each Python project to keep the dependencies separate. You can create a virtual environment by running the following command in your terminal:
python -m venv myenv - Activate the virtual environment: Activate the virtual environment to ensure that the packages you install are isolated to your project. On Windows, run:
myenv\Scripts\activate
On macOS and Linux, run:source myenv/bin/activate - Install required libraries: Install the necessary libraries for web scraping using pip. Open your terminal and run the following commands to install the requests and BeautifulSoup libraries:
pip install requestspip install beautifulsoup4
With these steps completed, you now have a Python environment set up and ready for web scraping without code. You have installed the requests library to send HTTP requests to websites and the BeautifulSoup library to parse and extract data from HTML.
Remember to respect websites' terms of service and robots.txt files when scraping. Be mindful of the requests you send to avoid overloading servers or violating any legal or ethical guidelines.
Finding and Inspecting Tables on a Web Page
To scrape tables from a website, you first need to understand the HTML structure of the page. Here's how you can inspect the HTML and identify the table elements:
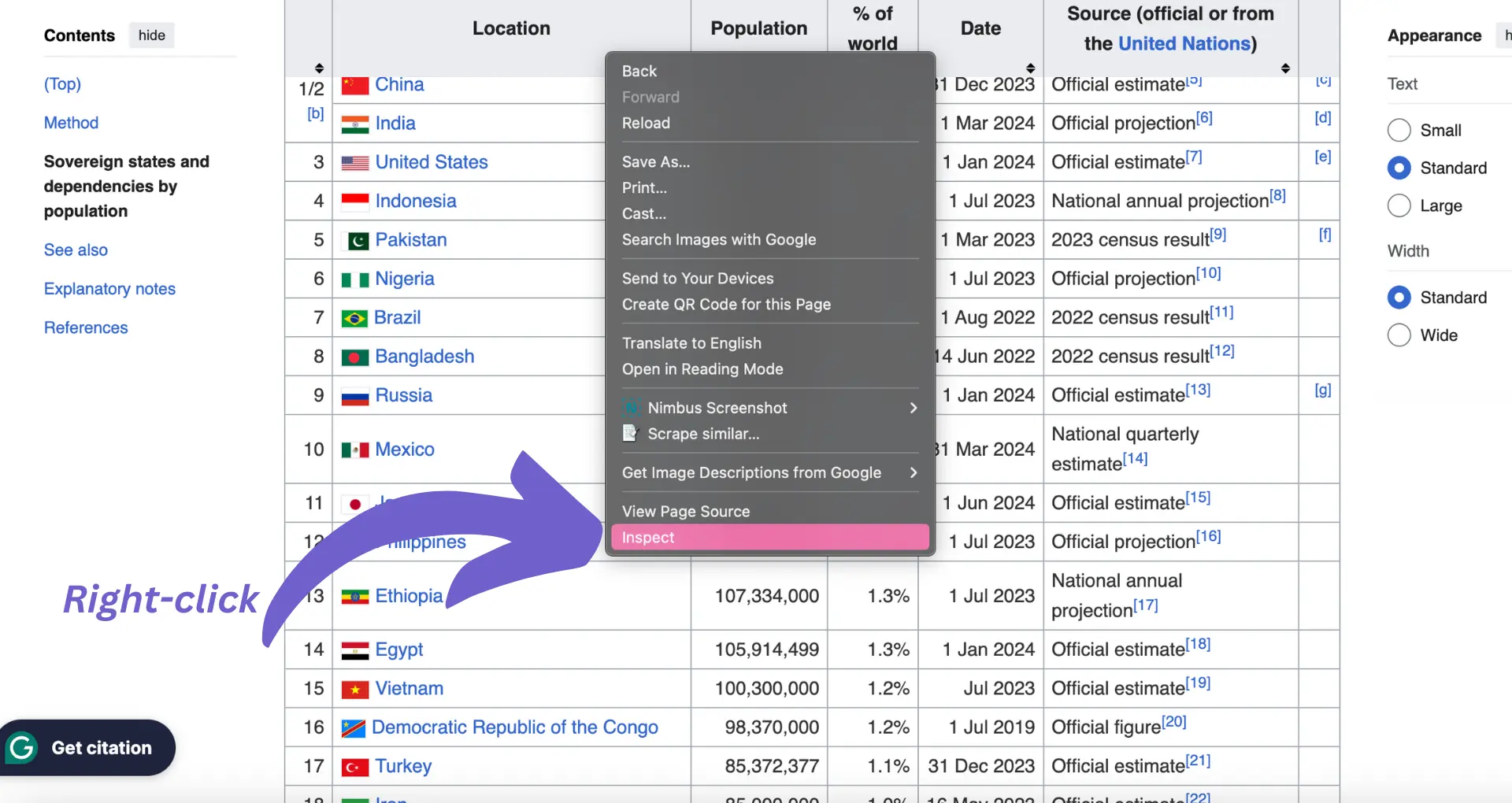
- Open the web page containing the table you want to scrape in your browser.
- Right-click on the table and select "Inspect" or "Inspect Element" from the context menu. This will open the browser's developer tools.
- In the developer tools, you'll see the HTML structure of the page. Look for the
<table>tag, which represents the table element. - Expand the
<table>tag to see its inner structure. You'll find<thead>for the table headers,<tbody>for the table body, and<tr>for each row within the table. - Inside the
<tr>tags, you'll see<th>for header cells and<td>for data cells.
Understanding the table structure is crucial for writing the appropriate code to extract the desired data. Take note of any specific class names, IDs, or attributes assigned to the table or its elements, as these can be used to target the table when scraping.
For example, if the table has a unique class name like <table class="data-table">, you can use that class name in your scraping code to specifically select that table.
By inspecting the HTML and identifying the table structure, you'll be able to write precise and efficient code to extract the data you need. In the next section, we'll dive into using Python and BeautifulSoup to scrape the table data based on the HTML structure we've identified.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Using Python and BeautifulSoup to Scrape Tables
Now that you've identified the table structure, it's time to extract the data using Python and the BeautifulSoup library. Here's a step-by-step guide to web scraping:
- Install the required libraries:
pip install requests beautifulsoup4 - Import the necessary modules in your Python script:
import requests
from bs4 import BeautifulSoup - Send a GET request to the URL containing the table you want to scrape:
url = "https://example.com/table-page"
response = requests.get(url) - Create a BeautifulSoup object by passing the response content and specifying the parser:
soup = BeautifulSoup(response.content, "html.parser") - Find the table element using the appropriate selector (e.g., class name, ID):
table = soup.find("table", class_="data-table") - Extract the table headers:
headers = []
for th in table.find_all("th"):
headers.append(th.text.strip()) - Extract the table rows:
rows = []
for row in table.find_all("tr"):
cells = []
for td in row.find_all("td"):
cells.append(td.text.strip())
if cells:
rows.append(cells) - Process the extracted data as needed (e.g., save to a file, perform analysis).
Here's an example of the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/table-page"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find("table", class_="data-table")
headers = []
for th in table.find_all("th"):
headers.append(th.text.strip())
rows = []
for row in table.find_all("tr"):
cells = []
for td in row.find_all("td"):
cells.append(td.text.strip())
if cells:
rows.append(cells)
# Process the extracted data
print(headers)
for row in rows:
print(row)
This code will print the table headers and rows extracted from the specified URL. You can modify the code to save the data to a file or perform further analysis based on your requirements.
BeautifulSoup provides a convenient way to navigate and extract data from HTML documents. By using the appropriate selectors and methods, you can easily scrape tables and other structured data from web pages.
Automating Data Extraction with Google Sheets
Google Sheets offers a convenient way to scrape table data from websites without the need for coding. The built-in IMPORTHTML function allows you to extract tables and lists directly into your spreadsheet. Here's how to use it:
- Open a new Google Sheet and select a cell where you want the data to appear.
- In the cell, enter the following formula:
=IMPORTHTML("URL", "table", index)Replace "URL" with the web page address containing the table you want to scrape. The "table" parameter specifies that you want to extract a table (you can also use "list" for lists). The index is the position of the table on the page (1 for the first table, 2 for the second, etc.). - Press Enter, and the table data will be imported into your sheet.
For example, to scrape the first table from Wikipedia's list of largest cities, use:=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_largest_cities","table",1)
Some tips for using IMPORTHTML:
- If the table structure changes on the website, your imported data may break. Regularly check and update your formulas.
- Be aware of the website's terms of service and robots.txt file to ensure you're allowed to scrape the data.
- Large tables may slow down your sheet. Consider importing only the necessary data or using a standalone web scraping tool for more complex tasks.
With IMPORTHTML, you can easily pull data from the web into Google Sheets for further analysis and reporting. Experiment with different URLs and table indexes to automate your data extraction workflows.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Advanced Techniques: Dynamic Data and JavaScript-Rendered Pages
Scraping dynamic websites that load data with JavaScript presents unique challenges compared to static pages. The content viewed in the browser may not match the HTML source code retrieved from the site, as JavaScript executes and modifies the page elements. To handle these situations, you have two main options:
- Use headless browsers like Selenium or Puppeteer to execute the page's internal JavaScript while scraping.
- Directly access the data from JavaScript APIs or parse JSON embedded in the page.
Headless browsers automate web interactions and render the complete page, allowing you to scrape the fully-loaded content. Tools like Selenium (with Python bindings) and Puppeteer (with the Pyppeteer library) provide APIs to control the browser, navigate pages, and extract data.
When using headless browsers, you can locate elements using methods like find_element_by_xpath() or CSS selectors, interact with forms and buttons, and wait for dynamic content to load. However, this approach can be slower and more resource-intensive than scraping static pages.
Alternatively, some dynamic sites load data via JavaScript APIs or store it as JSON within the page. By inspecting the network tab in browser dev tools, you may find XHR requests that return the desired data. You can then mimic these requests in your scraper to fetch the JSON directly, parsing it with libraries like requests and json.
The choice between using headless browsers or accessing data directly depends on the website's structure and your project's requirements. Headless browsers offer flexibility but may be overkill for simpler cases where data is readily available in JSON format.
Whichever approach you choose, be prepared to analyze the page's JavaScript code, monitor network requests, and adapt your scraping techniques to handle the dynamic nature of the website. With the right tools and strategies, you can successfully extract data from even the most complex JavaScript-rendered pages.
After successfully scraping data from websites, the next crucial step is to store and manage the collected information effectively. Proper data storage and management ensure that the scraped data remains organized, accessible, and ready for analysis. Here are some best practices and tools to consider:
- Data Cleaning: Before storing the scraped data, it's essential to clean and preprocess it. This involves removing any irrelevant or duplicate information, handling missing values, and standardizing the data format. Python libraries like Pandas and NumPy provide powerful functions for data cleaning and manipulation.
- File Formats: Choose an appropriate file format for storing the scraped data. Common options include CSV (Comma-Separated Values) and JSON (JavaScript Object Notation). CSV is suitable for tabular data and can be easily imported into spreadsheet applications like Microsoft Excel. JSON is more flexible and can handle hierarchical or nested data structures.
- Databases: For larger datasets or long-term storage, consider using a database management system (DBMS). Relational databases like MySQL and PostgreSQL are widely used for structured data. They provide efficient querying, indexing, and data integrity features. NoSQL databases like MongoDB and Cassandra are suitable for unstructured or semi-structured data and offer scalability and flexibility.
- Data Pipelines: Implement a data pipeline to automate the process of extracting, transforming, and loading (ETL) the scraped data into a storage system. Tools like Apache Airflow, Luigi, or AWS Glue can help orchestrate and schedule data pipelines, ensuring a smooth flow of data from the source to the target storage.
- Cloud Storage: Leverage cloud storage services like Amazon S3, Google Cloud Storage, or Microsoft Azure Blob Storage for scalable and reliable data storage. These services provide high availability, durability, and easy integration with other cloud-based tools and services.
- Data Versioning: Implement a versioning system to keep track of changes made to the scraped data over time. Tools like DVC (Data Version Control) or Git LFS (Large File Storage) enable version control for datasets, allowing you to track modifications, collaborate with others, and revert to previous versions if needed.
In addition to these practices, it's important to consider data security and privacy. Ensure that sensitive or personal information is properly anonymized or encrypted before storing it. Regularly backup your data to prevent loss due to hardware failures or other issues.
For data analysis and manipulation, popular tools include:
- Pandas: A powerful Python library for data manipulation and analysis. It provides data structures like DataFrames and Series, along with functions for filtering, grouping, and transforming data.
- SQL: Structured Query Language (SQL) is the standard language for interacting with relational databases. It allows you to retrieve, filter, and aggregate data using declarative queries.
- Jupyter Notebooks: An interactive development environment that combines code, visualizations, and narrative text. Jupyter Notebooks are widely used for data exploration, analysis, and presentation.
By following best practices and leveraging the right tools, you can effectively store, manage, and analyze the data scraped from websites. This enables you to gain valuable insights, make data-driven decisions, and unlock the full potential of the scraped information.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen workflows to streamline your data storage and analysis.
Legal and Ethical Considerations in Web Scraping
Web scraping has become an essential tool for businesses and individuals to gather valuable data from websites. However, it is crucial to consider the legal and ethical implications of web scraping to ensure responsible and compliant data collection practices. Here are some key considerations:
- Website Terms of Service: Before scraping any website, carefully review their terms of service or terms of use. Many websites explicitly prohibit or restrict web scraping activities. Violating these terms can lead to legal consequences, such as cease and desist orders or even lawsuits.
- robots.txt File: Check the website's robots.txt file, which specifies the rules for web crawlers and scrapers. This file indicates which parts of the website are allowed or disallowed for scraping. Respecting the instructions in the robots.txt file is considered a best practice and helps maintain a positive relationship with website owners.
- Data Ownership and Copyright: Consider the ownership and copyright of the data you intend to scrape. Some websites may have exclusive rights to the content they publish, and scraping such data without permission could infringe on their intellectual property rights. It's important to ensure that you have the necessary permissions or that the data falls under fair use or public domain.
- Personal Data and Privacy: Be cautious when scraping websites that contain personal or sensitive information. Collecting and using such data without proper consent or in violation of privacy laws, such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA), can lead to severe penalties and reputational damage.
- Scraping Frequency and Server Load: Respect the website's server resources and avoid aggressive scraping that could overload or disrupt their services. Implement reasonable delays between requests and limit the scraping frequency to minimize the impact on the website's performance. Excessive or abusive scraping practices can be considered a denial-of-service attack.
- Data Accuracy and Integrity: Ensure that the data you scrape is accurate, up-to-date, and free from any manipulations or distortions. Scraping outdated or incorrect data can lead to flawed analyses and decision-making. Regularly validate and verify the scraped data to maintain its integrity.
- Attribution and Giving Back: Consider attributing the source of the scraped data and providing value back to the website owner whenever possible. This can include linking back to the original content, citing the source, or sharing insights derived from the scraped data. Building a mutually beneficial relationship with website owners can foster a more positive and sustainable scraping ecosystem.
To scrape responsibly and ethically, consider the following tips:
- Use API-first approach: Many websites offer official APIs that provide structured and permissioned access to their data. Prioritize using APIs whenever available, as they are designed for data retrieval and often come with clear usage guidelines.
- Be transparent: Identify yourself and your scraping tool through user agent strings or by providing contact information. This transparency allows website owners to reach out to you if they have concerns or questions about your scraping activities.
- Respect data privacy: Implement measures to protect personal data, such as anonymization or pseudonymization, when scraping and storing data. Adhere to privacy laws and regulations applicable to your jurisdiction and the website's location.
- Seek permission when necessary: If you intend to scrape data for commercial purposes or in a way that may impact the website's operations, consider reaching out to the website owner to seek explicit permission or discuss a mutually beneficial arrangement.
By following these legal and ethical considerations, you can engage in web scraping responsibly, mitigate risks, and build trust with website owners and the wider data community. Remember, the goal is to leverage web scraping for valuable insights while respecting the rights and interests of all parties involved. Web scraping tools like Bardeen can help automate the process while adhering to best practices.
Automate Web Scraping with Bardeen Playbooks
Web scraping tables from websites can be a manual task, involving the identification of HTML elements and possibly writing custom scripts to extract the desired data. However, with Bardeen, you can automate this process, saving time and avoiding the need for programming knowledge. Automating web scraping can be particularly useful for gathering structured data from multiple pages or websites efficiently, such as extracting product information, stock levels, or contact details.
Here are some examples of how Bardeen can automate web scraping tasks:
- Extract information from websites in Google Sheets using BardeenAI: This playbook automates the extraction of any information from websites directly into a Google Sheet, streamlining data collection for analysis or reporting.
- Get web page content of websites: Automate the extraction of website content into Google Sheets, useful for content analysis, SEO audits, or competitive research.
- Get / scrape Google Search results for a keyword and save them to Airtable: This playbook scrapes Google search results for a given query and saves them to Airtable, facilitating market research or SEO analysis.
By leveraging Bardeen's playbooks, you can automate the tedious process of web scraping, allowing you to focus on analyzing the data. Explore more by downloading the Bardeen app at Bardeen.ai/download.

with Bardeen
Bardeen is the most popular Chrome Extension to automate your apps. Trusted by over 200k users.

.svg)
.svg)
.svg)
